Los modelos de IA pueden analizar miles de palabras a la vez: un investigador de Google ha descubierto cómo aumentar esa cifra en millones

Getty
- Un reciente trabajo de investigación revela una nueva forma de ayudar a los modelos de IA a absorber muchos más datos.
- "Ring Attention" elimina un importante cuello de botella de memoria para los modelos de IA.
- Según los investigadores, pronto será posible poner millones de palabras en ventanas contextuales de modelos de IA.
Ahora mismo, ChatGPT puede ingerir unos pocos miles de palabras como máximo. Los modelos de IA más grandes pueden procesar más, pero sólo hasta 75.000 palabras.
¿Qué pasaría si se pudieran introducir millones de palabras, bases de código completas o vídeos de gran tamaño en estos modelos?
Un investigador de Google, junto con el director de tecnología de Databricks, Matei Zaharia, y el profesor de la Universidad de Berkeley Pieter Abbeel, han encontrado la manera de hacerlo.
El avance, revelado en un reciente artículo de investigación que aún debe pasar la revisión por pares, promete cambiar radicalmente la forma en que interactuamos con estas nuevas y potentes herramientas tecnológicas.
El método actual no puede procesar grandes volúmenes de datos debido a las limitaciones de memoria de las GPU que entrenan y ejecutan los modelos de IA.
En la industria, todo esto se mide y discute basándose en "tokens" y "ventanas de contexto". Un token es una unidad que puede representar una palabra, o un fragmento de una palabra, un número o algo similar. La ventana de contexto es el espacio en el que se introduce una pregunta, un texto u otros datos en un chatbot o modelo de IA para que analice el contenido y escupa algo inteligente.
La startup de IA Anthropic y su chatbot Claude tienen una ventana contextual de hasta 100.000 tokens, lo que equivale aproximadamente a 75.000 palabras. Es decir, básicamente equivale a que el sistema puede leer un solo libro a la vez y hacer cosas inteligentes con él.
El modelo GPT-3.5 de OpenAI tiene una longitud de contexto de 16.000 tokens. El de GPT-4 es de 32.000. Un modelo creado por MosaicML, propiedad de Databricks, puede procesar 65.000 tokens, según el reciente trabajo de investigación.

Un nuevo modelo revolucionario
Hao Liu, estudiante de doctorado de la UC Berkeley e investigador a tiempo parcial en Google DeepMind, es coautor del artículo, titulado 'Ring Attention with Blockwise Transformers for Near-Infinite Context' ('Atención circular con transformadores de bloqueo para un contexto casi infinito').
Poco después de la publicación del artículo, le hice una entrevista por videoconferencia. Parece muy joven, es muy inteligente y capaz de explicar parte de la compleja tecnología que hay detrás de su idea.
Se trata de un giro sobre la arquitectura Transformer original que revolucionó la IA en 2017 y constituye la base de ChatGPT y de todos los nuevos modelos que han aparecido en los últimos años, como GPT-4, Llama 2 y el Gemini, el futuro modelo lingüístico de gran tamaño de Google.
La idea básica es que los modelos modernos de IA procesan los datos de una manera que requiere que las GPU almacenen varias salidas internas y luego las recomputen antes de pasar a la siguiente GPU.
Esto requiere mucha memoria y simplemente no hay suficiente. Esto acaba limitando la cantidad de datos que puede procesar un modelo de IA. Por muy rápida que sea la GPU, existe un cuello de botella de memoria.
"El objetivo de esta investigación era eliminar este cuello de botella", explica Liu.
El nuevo método que ha creado con Zaharia y Abbeel forma una especie de anillo de GPUs que pasan fragmentos del proceso a la siguiente GPU mientras reciben simultáneamente bloques similares de su otra GPU vecina. Y así sucesivamente.
"Esto elimina de forma efectiva las limitaciones de memoria impuestas por los dispositivos individuales", escriben los investigadores refiriéndose a las GPU.
La explicación se ha simplificado hasta un nivel sumamente básico. Pero el resultado final es lo realmente importante.
Ventanas contextuales gigantescas
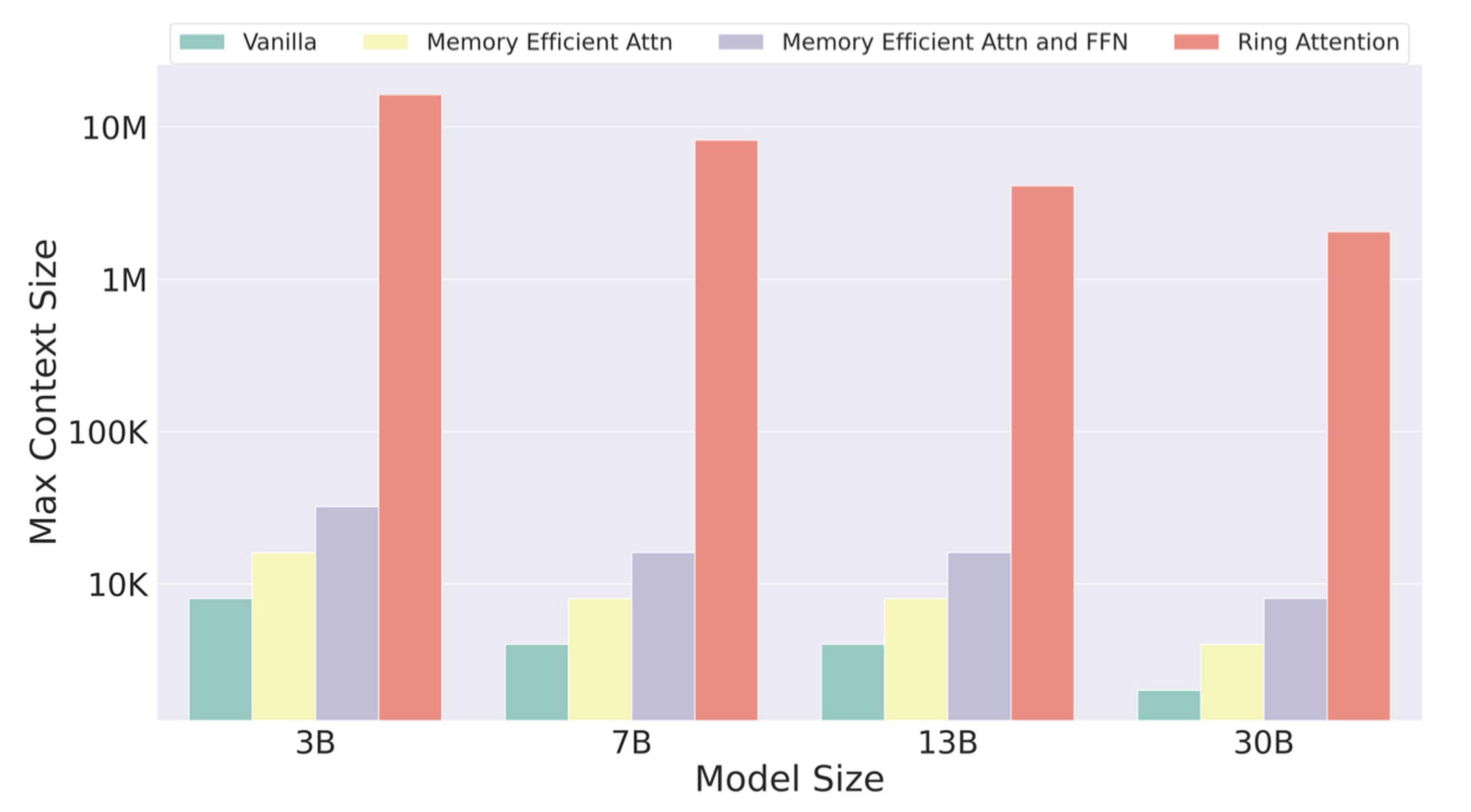
Este método de Ring Attention significa que deberíamos ser capaces de introducir millones de palabras en las ventanas de contexto de los modelos de IA, y no sólo decenas de miles.
Liu va más allá y afirma que, en teoría, en el futuro se podrán introducir de una sola vez muchos libros e incluso vídeos en las ventanas contextuales, y los modelos de IA los analizarán y producirán respuestas coherentes.
"Un modelo de IA podría leer un código fuente entero, o generarlo", afirma Liu. "Cuantas más GPU tengas, más larga puede ser ahora la ventana de contexto. Si no tienes GPU, no puedes permitirte ese lujo. Será emocionante ver lo que construyen las grandes compañías tecnológicas, las ricas en GPU".
Hao Liu, Matei Zaharia, Pieter Abbeel, UC Berkeley
Los investigadores lo han probado en experimentos reales. Le pregunté a Liu si le preocupaba que el método no funcionara. Su respuesta fue muy propia de Google.
"No me preocupaba", afirma. "Se puede calcular matemáticamente".
Con la forma actual de hacer las cosas, si tienes una ventana de contexto de 16.000 tokens, con un modelo de IA de 13.000 millones de parámetros que depende de 256 GPU Nvidia A100, la longitud del contexto está limitada a 16.000, explica.
Con el enfoque de Ring Attention, la misma configuración podría procesar una ventana de contexto de 4 millones de tokens.
No son malas noticias para Nvidia
Estos resultados plantean una pregunta importante: si se puede hacer más con menos GPU, ¿significará eso una menor demanda de los chips de IA de Nvidia?
No, según Liu. En su lugar, los desarrolladores y las empresas tecnológicas intentarán hacer cosas más grandes y atrevidas con esta nueva técnica.
"Ring Attention no desalentará la venta de GPU", añade. "Si se necesitan GPU, se seguirán necesitando más GPU".
Otros artículos interesantes:
Conoce cómo trabajamos en Business Insider.